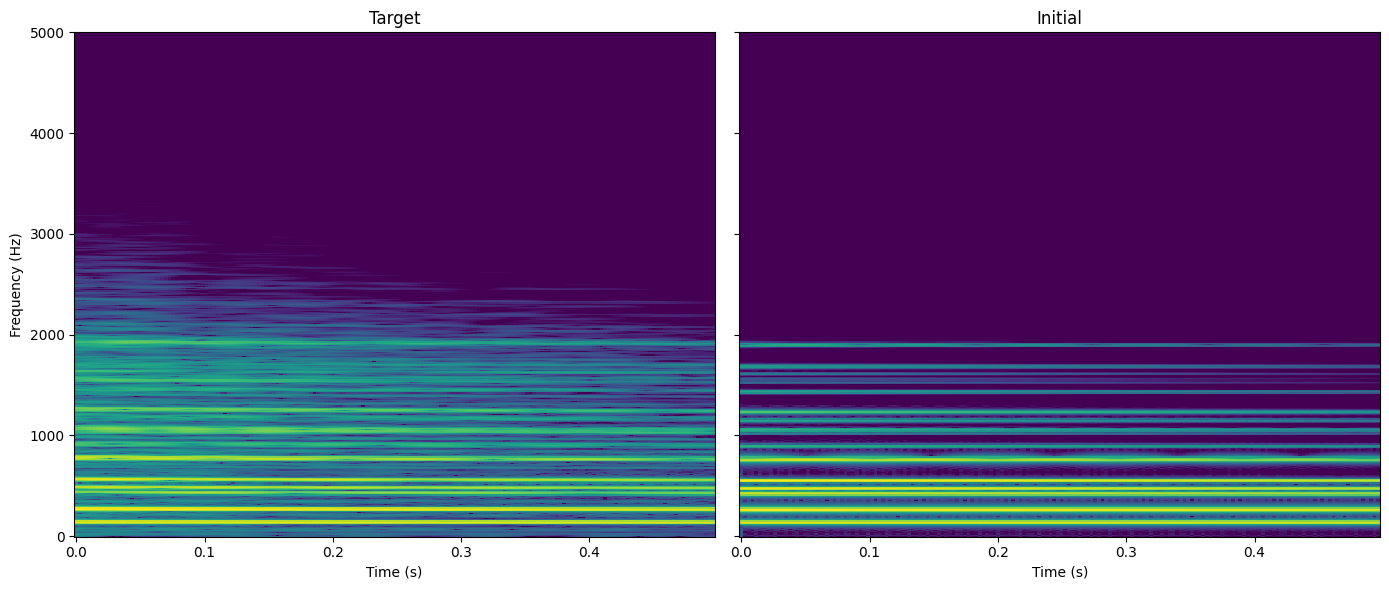
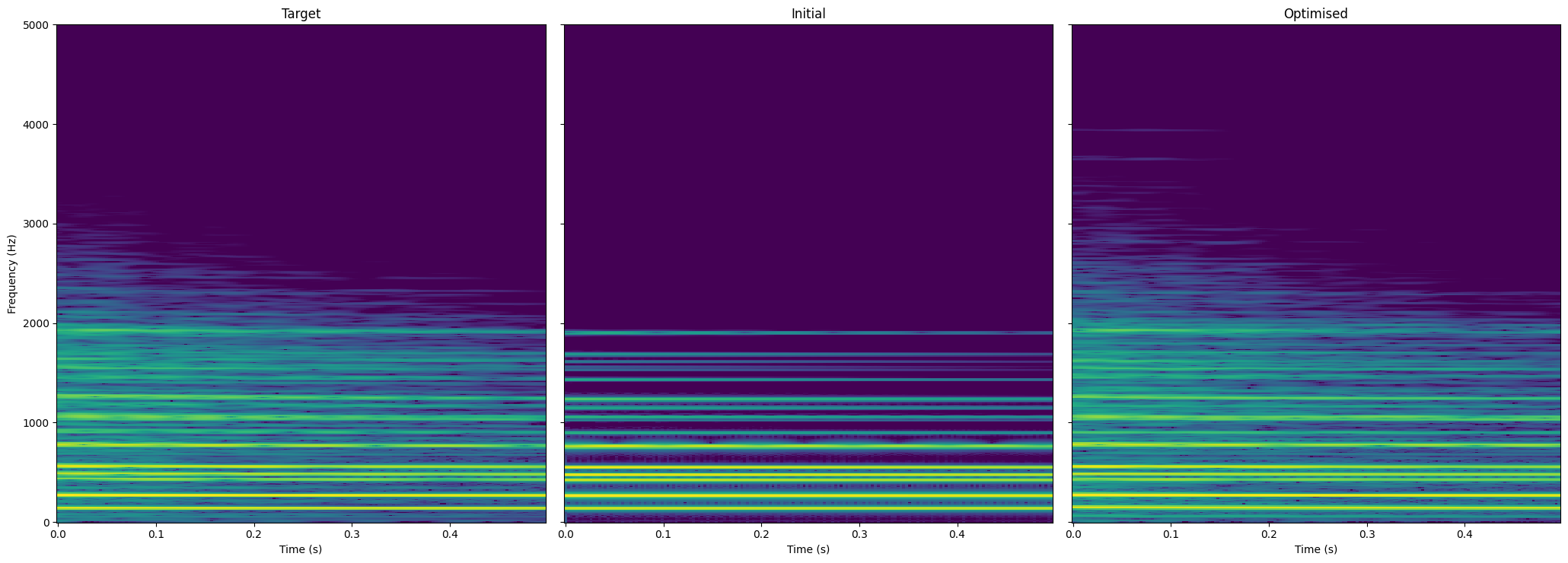
Optimising the coupling coefficients of the Von Karman plate model
We can also optimise the non-linearity part of the plate model, that is the coupling coefficients.
Again, we generate a target simulation of the plate. We define the parameters of the plate and the excitation.
Code
n_modes =20sampling_rate =44100sampling_period =1/ sampling_rateh =0.004# grid spacing in the lowest resolutionnx =50# number of grid points in the x direction in the lowest resolutionny =75# number of grid points in the y direction in the lowest resolutionlevels =2# number of grid refinements to performamplitude =0.5params = PlateParameters( E=2e12, nu=0.3, rho=7850, h=5e-4, l1=0.2, l2=0.3, Ts0=100,)force_position = (0.05, 0.05)readout_position = (0.1, 0.1)